The NSDC Data Science Flashcards series will teach you how the data pipeline is developed for data science projects. This installment of the NSDC Data Science Flashcards series was created by Emily Rothenberg, National Student Data Corps (NSDC) Program Manager. You can find these videos on the NEBDHub Youtube channel.
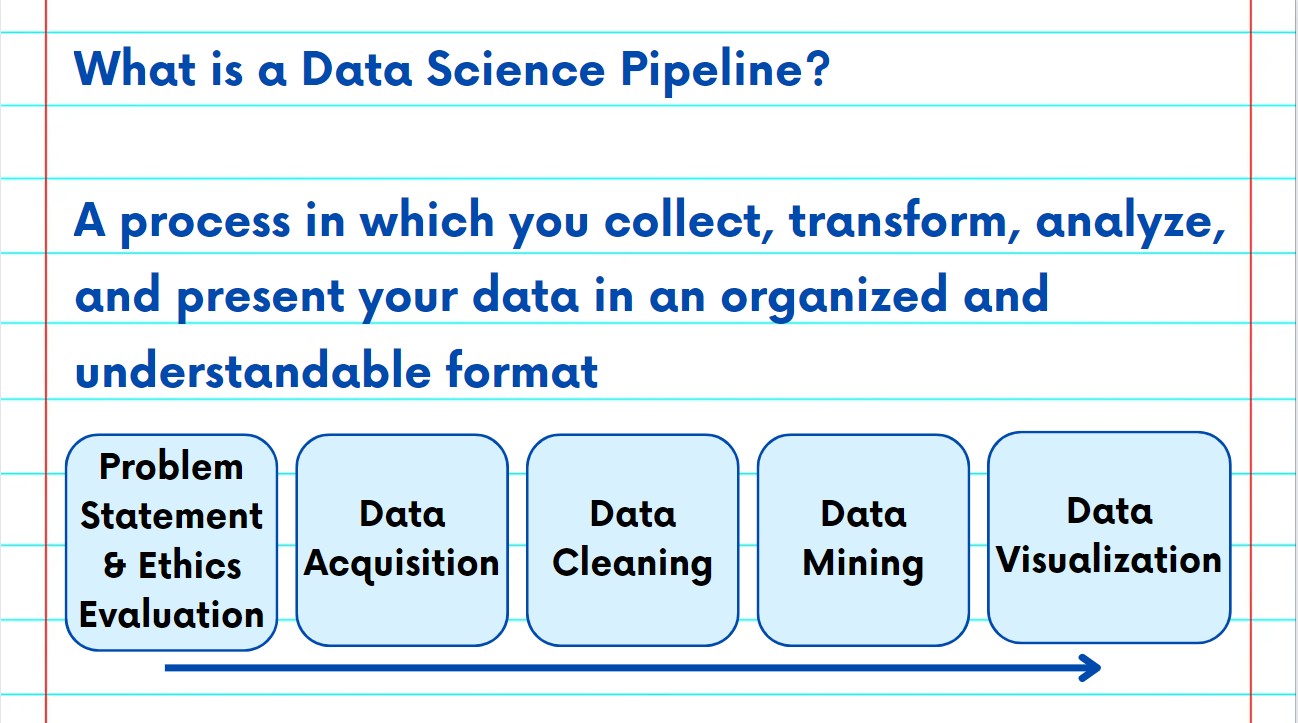
The fourth step in the Data Pipeline is Data Mining. Data Mining is a process of sorting and analyzing a large set of data to identify patterns, trends, and relationships within your data.
Data mining is useful because it allows corporations, individuals, and other users to gather information from their data to assist them in making recommendations or decisions. There are various algorithms and techniques that allow you to convert these large amounts of data into useful outputs.
- Association rules use machine learning to find patterns or other interesting associations in a very large dataset.
- Classification uses prior data observations and categories to properly classify data into its proper subpopulation.
- Clustering finds related items within a dataset and groups them together, allowing for analysis of what data fits into which groups, and what data is completely outlying.
- Decision trees take input values and predict target variables, all visualized as an upside down binary tree, allowing for easy interpretation and practicality for small datasets.
- Neural networks use artificial intelligence to mimic the human brain, taking input and processing it like neurons to better manage large amounts of data.
These techniques are leveraged in a variety of domains, including marketing and advertising, health care, customer services, sales, and manufacturing.

A company may want to determine which days of the week they should offer a discount code to their shoppers. Data Mining can be leveraged here to help them make that decision.
Please follow along with the rest of the NSDC Data Science Flashcard series to learn more about the Data Pipeline.