The NSDC Data Science Flashcards series will teach you how the data pipeline is developed for data science projects. This installment of the NSDC Data Science Flashcards series was created by Sneha Dahiya, a graduate student majoring in Business Analytics. You can find these videos on the NEBDHub Youtube channel.
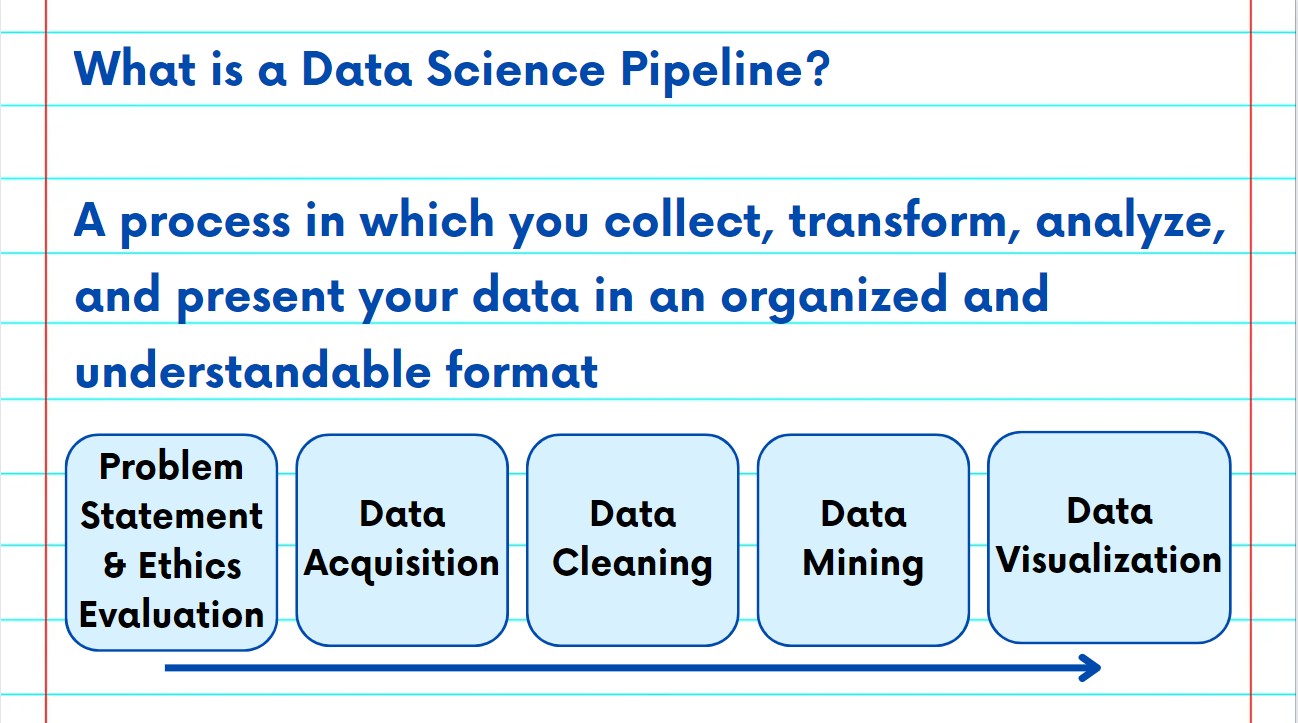
The third step in the Data Pipeline is Data Cleaning. Data Cleaning is a part of data pre-processing that removes the inconsistencies and prepares and validates the data before the main analysis can be performed.

These inconsistencies may include duplicate values or missing or inaccurate information. Additionally, Data Cleaning involves standardizing the data, handling outliers and ensuring uniform encoding and formatting.
For example, let’s consider a large time series dataset. The data may not be formatted with a standard date structure. Dates can be formatted as Day-Month-Year, DD/MM/YYYY, Month-Day-Year, MM/DD/YYYY, etc. So as a part of the data cleaning process, it is really important to follow a uniform format for reducing ambiguity.
Please follow along with the rest of the NSDC Data Science Flashcard series to learn more about the Data Pipeline.